Jede Spalte in der Übersichtstabelle zu den in GESStabs verfügbaren Signifikanztests entspricht einem Testverfahren, dessen theoretische Grundlagen an dieser Stelle erklärt werden:
Ergänzend wird auf
eingegangen, für die es für alle Testverfahren ein Pendant gibt.
Ein Kommentar vorab: Signifikanz und Gewichtung
Die Frage nach der Signifikanz eines in der Stichprobe beobachteten Unterschieds z.B. zwischen zwei Mittelwerten ist bei gewichteten Daten nicht ganz einfach zu beantworten. Inhaltlich ist die Frage nach der Signifikanz eines Unterschieds eines Messwerts in zwei Stichproben die Frage danach, wie (un)wahrscheinlich es ist, dass man aus der Grundgesamtheit eine Zufalls-stichprobe mit einem Unterschied (z.B. zwischen den Männern und den Frauen) zieht, obwohl dieser in der Grundgesamtheit nicht existiert.
Grundlage aller Wahrscheinlichkeitsabschätzungen ist das Modell der Ziehung aus der theoretischen Urne. Einer (Teil-)Stichprobe mit N Befragten entsprechen N Ziehungsvorgänge. Das aber ist bei gewichteter Tabellierung offensichtlich nicht der Fall: wenn ein Befragter das Gewicht von z.B. 2,34 hat, konnte er trotzdem nur 1.0-mal zufällig aus der Grundgesamtheit ausgewählt werden, und die Anzahl dieser Auswahlvorgänge ist Ausgangspunkt der Überlegungen zur Signifikanz. Die Ausweisung von Signifikanzen in gewichteten Tabellen ist also nicht unproblematisch und die verschiedenen möglichen Vorgehensweisen sind mit Vor- und Nachteilen behaftet, die man gegeneinander abwägen muss. GESStabs bietet für die gängigsten Fragestellungen durchgängig vier Verfahren an, wie man mit diesem Problem umgehen kann, die weiter unten die vier Spalten der Matrix bilden.
Im Standardfall verwendet GESStabs die Summe der Gewichte als Grundlage der Signifikanzberechnungen (erste Spalte in der Übersichtstabelle). Das ist nach dem oben Ausgeführten bei gewichteten Datensätzen nicht wirklich korrekt. Es ist als Näherung vertretbar, solange die Gewichte sich nicht erheblich von 1.0 unterscheiden. Da die Gesamtsumme der Gewichte der Anzahl der Fälle entspricht, kommt es zu einer gewissen Nivellierung der Effekte, da Gewichte größer als 1 eben auch Gewichte kleiner als 1 bedingen. Der Vorteil dieser einfachen Methode ist, dass die Berechnungen zu Anteilwerten und zur Signifikanz auf denselben Daten beruhen: Ergebnisse und Signifikanzdarstellung sind in diesem Sinne kongruent.
Man verwendet im Falle der gewichteten Darstellung einfach dieselben CELLELEMENTS wie auch bei der ungewichteten: COLCHIQU etc.
Eine Alternative ist, für die Signifikanzberechnung die ungewichteten Werte heranzuziehen (zweite Spalte in der Übersichtstabelle). Man weist also dann die Signifikanz für einen Unterschied aus, wenn dieser Zusammenhang in den ungewichteten Rohdaten besteht. Damit ist die Bedingung erfüllt, dass jeder Fall mit derselben Chance in die Stichprobe gekommen ist. Das ist der Vorteil; der Nachteil ist, dass ein Unterschied getestet wird, der so in den Tabellen nicht ausgewiesen ist und numerisch davon abweichen kann. Den entsprechenden CELLELEMENTS ist zur Kennzeichnung der ungewichteten Vorgehensweise die Kennung 'PHYS' wie PHYSICALRECORD vorangestellt: PHYSTTEST, PHYSCOLCHIQU etc.
Es bietet sich unmittelbar an, die beiden ersten Methoden miteinander zu verknüpfen. GESStabs berechnet die Signifikanz nach der Methode (1) auf der Basis der Fallgewichte, und im Anschluss wird überprüft, ob dieser Unterschied auf der Basis der ungewichteten Fälle (2) ebenfalls besteht. GESStabs weist dann Signifikanz nur in dem Maße aus, wie beide Methoden dies unterstützen (dritte Spalte in der Übersichtstabelle).
Hiermit werden solche Signifikanzausweisungen unterdrückt, die lediglich auf der Basis der gewichteten Daten bestehen, also in gewissem Sinne erst durch die Gewichtung produziert wurden. Die hierfür zu verwendenden CELLELEMENTS sind durch ein vorangestelltes 'X' gekennzeichnet: XTTEST, XCOLCHIQU usw.
Bei der Betrachtung von Signifikanzen bei gewichteter Darstellung geht es vor allem darum, Artefakte auszuschließen. Eine andere Möglichkeit hierzu besteht darin, bei der Analyse des Unterschieds statt der Summe der Gewichte eine 'effektive Basis' zu verwenden, in der die Abweichung der Gewichte von 1.0 berücksichtigt wird (vierte Spalte in der Übersichtstabelle). Die hierfür üblicherweise verwendete 'effective sample size' heißt in GESStabs 'ESS' und steht auch als eigenes CELLELEMENT zur Verfügung. In diese Größe fließen die Summe der Gewichte (G) und die Summe der Quadrate der Gewichte (SQ) ein:
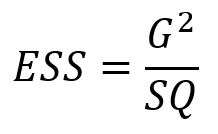
Es ist leicht zu sehen, dass ESS immer dann gleich der Anzahl der Fälle ist, wenn alle Gewichte die Größe 1.0 haben. Je weiter sich die Gewichte von 1.0 entfernen, um so kleiner wird die effektive Stichprobengröße ESS, da die Summe der Quadrate wächst. Daraus folgt, dass eine Signifikanzberechnung bei einem gegebenen Unterschied immer seltener eine kleine Fehlerwahrscheinlichkeit hat, je stärker die Gewichte sich von 1.0 unterscheiden. Die entsprechenden CELLELEMENTS in GESStabs sind durch die Vorsilbe 'ESS' gekennzeichnet.
Mit 'HY' sind die Mitglieder der Familie der hybrid ausgestalteten Tests gekennzeichnet (fünfte Spalte in der Übersichtstabelle). Die hybriden Tests für Anteilswerte gehen so vor, dass aus den gewichtet ermittelten Anteilswerten fiktive absolute Häufigkeiten auf der Basis der ungewichteten Randverteilung errechnet werden. Diese 'Absolutzahlen' gehen dann in die statistische Beurteilung ein. Die Tests zum Mittelwertsunterschied gehen so vor, dass die t-Werte auf Basis der gewichteten Daten errechnet werden, die Freiheitsgrade zur Berechnung der p-Werte der t-Verteilung ergeben sich aus den ungewichteten Häufigkeiten.
Die in GESStabs verwendeten hybriden Methoden sind ein Versuch, die Unterschiede, die in den gewichteten Daten sichtbar werden, anhand der ungewichteten Fallzahlen zu bewerten. Die Vorgehensweise wird hier beschrieben, damit der Nutzer sich ein Bild machen kann, wie GESStabs bei den hybriden Tests vorgeht, um zu entscheiden, ob er diesem Vorschlag folgen will. Wir halten dieses Verfahren für angemessen. Es ist aber nichts, was man in statistischen Textbüchern finden kann.
Unabhängiger hybrider t-Test für zwei Stichproben (HYTTEST)
In die Berechnung des t-Wertes gehen die Stichprobengrößen mehrfach ein. In die Berechnung des zu untersuchenden Mittelwertunterschieds, bei der Schätzung der gemeinsamen Varianz bzw. Standardabweichung aus den Varianzen der Einzelstichproben, und in die Berechnung des t-Wertes selbst.
Beim hybriden t-Test werden die zu testenden Mittelwerte und die Varianzen der Einzelstichproben (V1 und V2) auf der Basis der gewichteten Daten ermittelt. Hieraus ergibt sich auch das zu bewertende ∆ der beiden Mittelwerte. Die Einzelvarianzen beider Stichproben werden gewichtet ermittelt.
In die dann folgenden Berechnungen zur Schätzung der gemeinsamen Varianz, des t-Werts und der Freiheitsgrade gehen hingegen die ungewichteten Stichprobengrößen (u1, u2) ein:
![]()
![]()
![]()
![]()
Abhängiger hybrider t-Test (HYCOLDEPTTEST)
Analog zur unabhängigen Variante wird auch beim abhängigen t-Test verfahren. Der Mittelwert und die Varianz der Abweichung ist das Ergebnis einer gewichteten Betrachtungsweise. In die Berechnung des t-Tests und der Anzahl der Freiheitsgrade geht die ungewichtete Fallzahl ein.
Unabhängiger hybrider Test auf Anteilsunterschieden (HYCOLCHIQU)
Basis des hybriden χ² -Tests sind die gewichteten gegeneinander zu testenden prozentualen Anteilswerte (p1, p2). Für jeden Anteilswert ist die ungewichtete Basis bekannt. Aus diesen Größen lässt sich eine fiktive ungewichtete Zellenbesetzung errechnen, die diesem Prozentwert entspräche. Diese Tabelle lässt sich zur vollständigen 4-Felder-Tafel erweitern, die dann Basis des χ² -Tests wird. Das Vorgehen hat also sehr große Ähnlichkeit zum Verfahren bei ESSCOLCHIQU, nur dass anstelle der ESS-Werte zur Bestimmung der Basenzeile die ungewichteten Fallzahlen herangezogen werden.
Abhängiger hybrider Test auf Anteilsunterschiede (HYMCNEMAR)
In der Veränderungsmatrix geht es um die Felder b und c. Diese werden zunächst gewichtet und ungewichtet ermittelt. Für die Schätzung der relativen Anteile der Fälle, bei denen eine Veränderung zu messen ist (eben b und c), ist die gewichtete Zählung maßgebend, da die Gewichtung ja idealerweise eine Verbesserung der Strukturanpassung bewirkt. Die absolute Größe der Zellenbesetzungen, die ja entscheidend in den McNemar Test eingeht, soll aber anhand der ungewichteten Zahl der Befragten errechnet werden. Seien bw und cw die gewichteten Besetzungen von b und c, und bu und cu die ungewichteten, dann ergibt sich die angepasste Besetzung b zu
")
(Berechnung von c analog)
Aus b und c ergibt sich die Testgröße 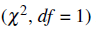 nach dem Standard-Berechnungsverfahren.
nach dem Standard-Berechnungsverfahren.
Der Test nach McNemar steht für alle oben aufgeführten Testverfahren (1.-5.) zur Verfügung und setzt voraus, dass für jeden zu untersuchenden Fall bzw. Befragten für zwei zu vergleichende Variablen jeweils ein Messwert bekannt ist. Hiervon gibt es zwei mögliche Abweichungen:
1.Für einen Fall sind eine oder beide Variablen MISSING: dies wird vom Algorithmus berücksichtigt und ist somit kein Problem. Die Anzahl der Freiheitsgrade für den Test wird entsprechend vermindert.
2.Für einen Fall enthält eine zu testende Variable mehr als einen Wert. Dies sollte eigentlich nicht vorkommen, da nur eindeutige kategoriale Variablen mit einem abhängigen Test sinnvoll getestet werden können. Da aber Tabellen mit MCNEMAR i.d.r. mit TABLE ADD-Konstrukten erzeugt werden, können auch aus der Addition mehreren atomarer Variablen Mehrfachnennungen entstehen. Alle Tests mit MCNEMAR enthalten jetzt eine Prüfung, die den Tabellierlauf in einem solchen Fall mit einer RunTime-Fehlermeldung abbricht.
Alternative zum Student´s t-Test
Der t-Test nach Welch ist für die tabellarische Darstellung besser geeignet, da die Homogenität der Varianzen nicht (wie bei Student´s t-Test) zu den Anwendungsvoraussetzungen zählt. Eine weitere Besonderheit des t-Test nach Welch ist die Tatsache, dass in die Berechnung der Freiheitsgrade für den t-Test auch die Varianz in den Zellen einfliesst. GESStabs berechnet die Freiheitsgrade im hybriden Test anhand der ungewichteten Zellenbesetzung (PHYSICALRECORDS) und der gewichteten Varianz in den Zellen.
Der t-Test auf Mittelwerteunterschiede nach Welch kann immer da eingesetzt werden, wo bislang TTEST und seine Varianten verwendet wurden.
Es kann zu unterschiedlichen Ergebnissen in der Signifikanzausweisung zwischen Student´s t-Test und dem t-Test nach Welch kommen: Der t-Test nach Welch ist 'konserativer' als der Student´s t-Test, d.h. der p-Wert, der über die Ausweisung einer Kennzeichnung entscheidet, kann ein wenig größer sein als bei Student. In Grenzfällen kann es also vorkommen, dass ein Zusammenhang, der nach Student noch als (grenzwertig) signifikant erscheint, bei Welch's t-Test nicht ausgewiesen wird.