In der Folge wird anhand einer Reihe von Tabellen beschrieben, wie mit dem TABLE-Statement verschiedene Tabellen generieren werden können.
TABLE, als Kernelement der Arbeit mit GESStabs, streift dabei viele Themen, die ausführlich in anderen Kapiteln und hier anhand von Beispielen behandelt werden:
Zur Beschreibung der verwendeten Variablen, siehe das Variablengerüst am Ende dieses Abschnitts.
Basis-Beispiel
Als einfachstes Beispiel können wir eine Tabelle machen, die zwei der Variablen gegeneinander tabelliert: "Alter" im Kopf, und die Frage "bekannt" in der Vorspalte:
TABLE = alter BY bekannt;
Das ist die einfachste Form eines GESStabs Tabellen-Statements: Nach dem Schlüsselwort TABLE schreibt man die Variable, die in den Kopf soll, dann folgt das Schlüsselwort BY, und dann die Variable, die in der Vorspalte stehen soll. Abgeschlossen wird die Anweisung, wie immer, durch das Semikolon.

Tabellenkopf und Tabellenvorspalte
Das TABLE-Statement beherrscht etwas über 100 verschiedene sogenannte CELLELEMENTS, also Inhalte, die in den einzelnen Zählzellen dargestellt werden können. Wir haben hier keine Spezifikation vorgenommen - GESStabs stellt in diesem Fall die absoluten Häufigkeiten dar (im Falle gewichteter Daten ist das die Summe der jeweiligen Fallgewichte).
Außerdem können verschiedene Elemente des Tabellenrahmens dargestellt werden, z.B. eine zusätzliche Totalspalte oder eine Zeile mit der jeweiligen absoluten Basis. Dies steuert die GESStabs-Anweisung FRAMEELEMENTS. Es gibt folgende drei Arten von Rahmenzeilen:
TOTALROW
ABSROW
PHYSICALROW
und folgende drei Arten von Rahmenspalten:
TOTALCOLUMN
ABSCOLUMN
PHYSICALCOLUMN.
Im Standardfall einer Tabelle mit absoluten Häufigkeiten ist von den sechs Rahmenelementen nur eines vorhanden: die Zeile mit den absoluten Häufigkeiten, ABSROW.
In unserem Fall sollen in den Zellen Spaltenprozente abgebildet werden, das heißt als CELLELEMENTS wählen wir COLUMNPERCENT. Dazu passen eine Totalspalte und eine Absolutzeile. Die Anweisungen werden vor dem TABLE-Statement gesetzt.
CELLELEMENTS = COLUMNPERCENT;
FRAMEELEMENTS = ABSROW TOTALCOLUMN;
TABLE = alter BY bekannt;

Zellen mit Spaltenprozenten
Dass die Tabelle optisch so aussieht, wie sie aussieht, liegt an der Formatdatei, die üblicherweise alle Anweisungen zur Tabellengestaltung bündelt. In der Formatdatei steht z.B.
FORMAT COLUMNPERCENT = "##.# %";
Dieses Format bewirkt die Darstellung der Spaltenprozente mit einem Prozentzeichen nach einem Leerzeichen und einer Nachkommastelle mit einem Dezimalpunkt. In der Formatdatei sind auch die zu verwendenden Schriftarten definiert, z.B.
USEFONT LABELS X = "Helvetica-Bold" size 9;
Erweiterter Tabellenkopf
In der Regel besteht der Tabellenkopf einer Tabelle nicht nur aus einer einfachen Variablen wie dem Alter in drei Stufen. Als nächstes soll ein Kopf mit zwei Variablen tabelliert werden. In den meisten Fällen werden Köpfe über #EXPAND definiert; man kann dann am einfachsten den Kopf für einen ganzen Tabellenband ändern, indem man einfach den Inhalt des #expand verändert.
#expand #k geschl alter
TABLE = #k BY bekannt;
Das kommt heraus:

Tabellenkopf mit zwei Variablen
Anstelle des VARTITLEs der Variablen "bekannt" über den Labeln würden wir lieber den Fragentext sehen. Dafür müssen wir zweierlei tun:
1. die Beschriftung mit dem VARTITLE ausschalten und
2. GESStabs eine Regel mitteilen, woher der Fragentext kommen soll. Man kann auch der Tabelle den Fragentext direkt mitgeben, aber wir wollen den in der Variablendefinition beschriebenen Text ja nicht immer wieder abtippen oder kopieren. Zitieren vermeidet Redundanz, und vermeidet damit Fehler.
... Weil wir dann schon mal bei den Verschönerungen sind: Außerdem sollen die Tabellen eine etwas inhaltsreichere Überschrift tragen: "GESStabs Beispiel Nr. <Tabellennummer>".
Das Vorgehen ist wie folgt:
1. VARTITLE ausschalten: Ob ein VARTITLE gedruckt werden soll oder nicht, ist eine der möglichen Optionen des TABLEFORMAT. TABLEFORMATs sind Voreinstellungen; einmal im Skript hingeschrieben, gelten sie, bis eine neue Voreinstellung kommt. Wir ergänzen vor dem TABLE-Statement:
TABLEFORMAT = +NOVARTITLEBOX;
2. Regel zum Fragentext. Es sollen immer die Texte ausgedruckt werden, die zu den in der Richtung der Y-Achse tabellierten Fragen gehören. Die Tabelle hat dafür zwei mögliche Plätze, den TOPTEXT und den BOTTOMTEXT. Meistens steht der Text oberhalb der eigentlichen Tabelle, unterhalb des TABLETITLE. Deshalb ergänzen wir:
CITEALLVARS = TOPTEXT YVALID;
Jetzt ändern wir noch den Tabellentitel:
TABLETITLE = "GESStabs Beispiel Nr. _";
Die Tabellierungsanweisung sieht jetzt insgesamt so aus:
TABLETITLE = "GESStabs Beispiel Nr. _";
CITEALLVARS = TOPTEXT YVALID;
TABLEFORMAT = NOVARTITLEBOX;
TABLE = #k BY bekannt;
Schauen wir jetzt das Ergebnis an:

Fragetexte einblenden
Übersichtlicher wäre es, wenn die Prozentwerte in der Totalspalte absteigend sortiert wären. Das ist inhaltlich gleichbedeutend damit, dass die zugrunde liegenden absoluten Häufigkeiten absteigend sortiert sind. Das kann man anfordern mit:
TABLE = #k BY bekannt SORT ABSOLUTE DESCEND;

Tabelle sortiert nach Totalspalte
Es werden noch zwei Tabellen hinzugefügt:
TABLE = #k BY gekauft SORT ABSOLUTE DESCEND;
TABLE = #k BY item_1;

Kategorien nach Labeleigenschaften darstellen
Anmerkung zur Abbildung: die Kategorie "Keine davon" ist ans Ende der Tabelle sortiert, obwohl der Zahlenwert nicht der kleinste ist. Dies geht zurück auf die Labeleigenschaft BOTTOM für diesen Labeltext. (Siehe die Variablendefinition, wie sie unten abgedruckt ist.)

Tabelle zu Item 1
Mittelwert
Bei der Betrachtung der Tabelle zu Item 1 kommt der Wunsch auf, neben der Häufigkeitsverteilung auch den Mittelwert zu sehen. Dafür wird das TABLE Statement um eine MEAN-Klausel erweitert. Man kann alle CELLELEMENTS auch als einfache Zeilen bzw. Spalten einer Tabelle zusätzlich anfordern. Mittelwerte und ähnliche Maßzahlen wie z.B. Varianz oder Median benötigen alle eine explizite Variable als Argument:
TABLE = #k BY item_1 mean :description "Mittelwert" ( item_1 ); 40

Ausgewiesener Mittelwert
Erweiterungen der CellElements und Beschriftungen
In den bis jetzt vorgestellten Tabellen ist in den einzelnen Datenzellen immer nur ein Wert dargestellt worden: Spaltenprozente. In den einzelnen Zellen einer Tabelle können aber mehrere Daten gleichzeitig dargestellt werden. GESStabs unterstützt bis zu sieben CELLELEMENTS je Zählzelle. Hierfür muss nur die CELLELEMENTS-Klausel erweitert werden, wir ergänzen hier zur Demonstration einmal die absolute Zellenbesetzung ABSOLUTE:
CELLELEMENTS = COLUMNPERCENT ABSOLUTE;
TABLE = #k BY item_1 mean :description "Mittelwert" ( item_1 );

Mehrere Werte pro Zelle
Tabellen kann man auch "nach unten" erweitern; z.B. können zwei Items auf einer Seite mit ihren dazugehörigen Mittelwerten dargestellt werden. Hierbei ist es allerdings u.U. übersichtlicher, nicht im TOPTEXT der Tabelle alle Fragentexte abzubilden, sondern es werden jeweils über die Ausprägungen der Items die VARTITLE ausgegeben.
CITEALLVARS = no;
TABLEFORMAT = -NOVARTITLEBOX;
CELLELEMENTS = COLUMNPERCENT;
table = #k by
item_1 mean :description "Mittelwert" ( item_1 )
item_2 mean :description "Mittelwert" ( item_2 )
;

Fragen als VARTITLE
Groups im Tabellenkopf
Oft enthalten Köpfe Spalten, die erst aus einer Kombination mehrerer Fragen bzw. Variablen hervor gehen. Solche Umformungen kann man am elegantesten mit dem GROUPS-Statement erledigen:
GROUPS Männer_k =
|
"18-29 Jahre" : alter EQ 1 AND geschl EQ 1
|
"30-49 Jahre" : alter EQ 2 AND geschl EQ 1
|
"50-64 Jahre" : alter EQ 3 AND geschl EQ 1
;
VARTITLE = "Männer";
GROUPS Frauen_k =
"18-29 Jahre" : alter EQ 1 AND geschl EQ 2
|
"30-49 Jahre" : alter EQ 2 AND geschl EQ 2
|
"50-64 Jahre" : alter EQ 3 AND geschl EQ 2
;
VARTITLE = "Frauen";
#expand #k Männer_k Frauen_k
Das oben verwendete GROUPS-Statement ist die übersichtlichste Art, eine neue DichoQ zu erzeugen. Der Vorteil liegt vor Allem darin, dass man die Texte und die dazu gehörigen Bedingungen auf einen Blick erfassen kann.
TABLE = #k BY bekannt SORT ABSOLUTE DESCEND;

Kombinierte Fragen / Variablen
Der Kunde möchte noch etwas Anderes: Könnte man die fünf Items nicht nebeneinander darstellen? Klar, kann man. Jetzt wird es allerdings etwas komplizierter, denn dies ist keine klassische Kreuztabelle mehr. Ein Weg, sich eine solche Tabelle vorzustellen, ist das Bild einer Addition; zuerst wird die erste Spalte mit der ersten Variablen gefüllt, dann die zweite Spalte mit der zweiten Variablen, und so weiter. Den Mechnismus des Addierens in Tabellen behandelt die Anweisung TABLE ADD.
Zunächst benötigen wir einen Kopf, der die fünf Items abbildet. Da dies im Tabelliererjargon eine Dummy-Variable ist, nennen wir sie "dummy5".
COMPUTE dummy5 = 1;
VARTITLE dummy5 = "5 Items nebeneinander";
LABELS dummy5 =
1 "Farbe wichtig"
2 "Sprach~qualität wichtig"
3 "Gute Ausstat~tung wichtig"
4 "Marke bevorzugt"
5 "Marke abgelehnt"
;
#expand #k3 dummy5
Danach können wir schreiben:
TABLEFORMAT = +NOVARTITLEBOX;
TABLE STRUCTURE = #k3 BY item_1;
TABLE ADD = 1 by item_1;
TABLE ADD = 2 by item_2;
TABLE ADD = 3 by item_3;
TABLE ADD = 4 by item_4;
TABLE ADD= 5 by item_5;
Das Tabellen-Statement besteht jetzt aus fünf TABLE-Statements; ein "normales" und dann folgen vier TABLE ADD-Statements. In den TABLE ADD-Zeilen des Skripts kann man anstelle der im Kopf stehenden Variablen einfach den Zahlenwert hinschreiben, der dem "passenden" Label entspricht. Und das kommt als Ergebnis dabei heraus:
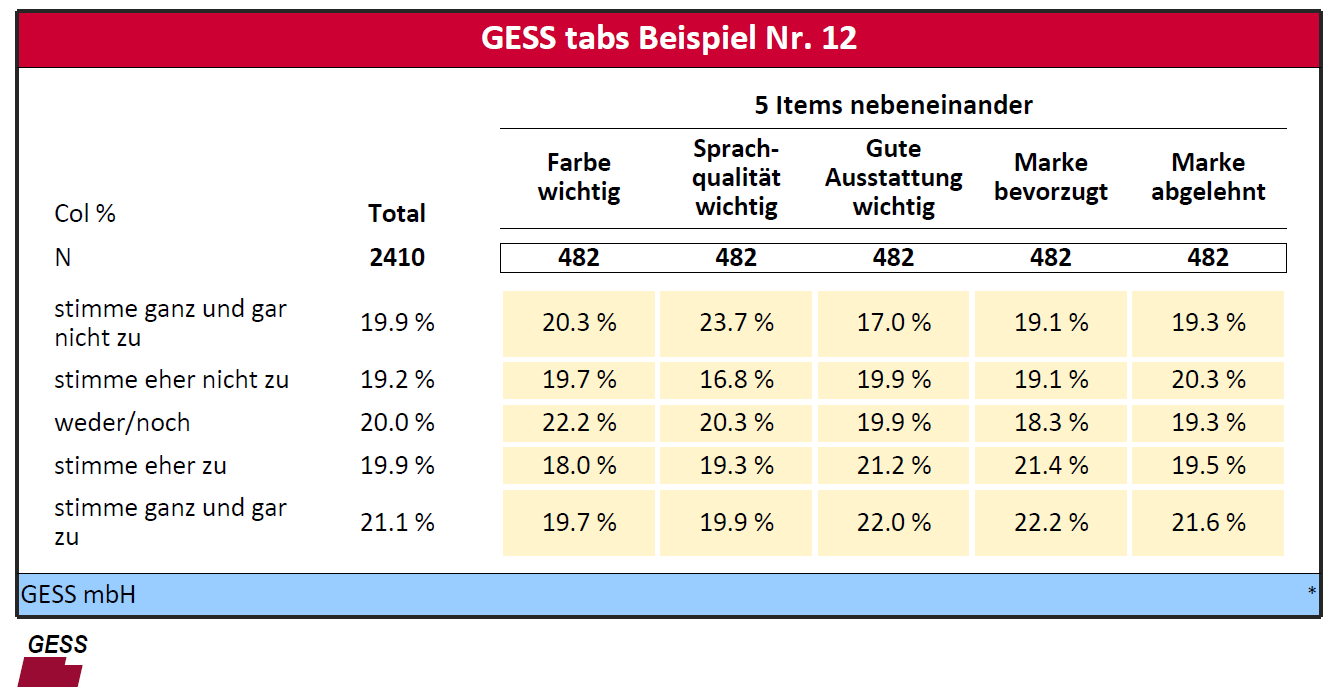
Bei Betrachtung der Tabelle zeigt sich, dass es nicht unbedingt sinnvoll ist, bei solchen Tabellen eine Totalspalte mitzuführen; sie ist zwar nicht im engeren Sinne falsch, kann aber schon etwas irreführend sein. Wir schalten die TOTALCOLUMN als FRAMEELEMENT also aus, und verwenden nur ABSROW.
Zusätzlich hätten wir aber gern wieder den Mittelwert der Items. Dafür muss in allen fünf Statements zusätzlich ein MEAN angefordert werden:
FRAMEELEMENTS = ABSROW;
TABLE
= #k3 by item_1 mean : description "Mittelwert" ( item_1 );
table add = 2
by item_2 mean : description "Mittelwert" ( item_2 );
table add = 3
by item_3 mean : description "Mittelwert" ( item_3 );
table add = 4
by item_4 mean : description "Mittelwert" ( item_4 );
table add = 5
by item_5 mean : description "Mittelwert" ( item_5 );
Und das ist die Tabelle, die wir dann erhalten:
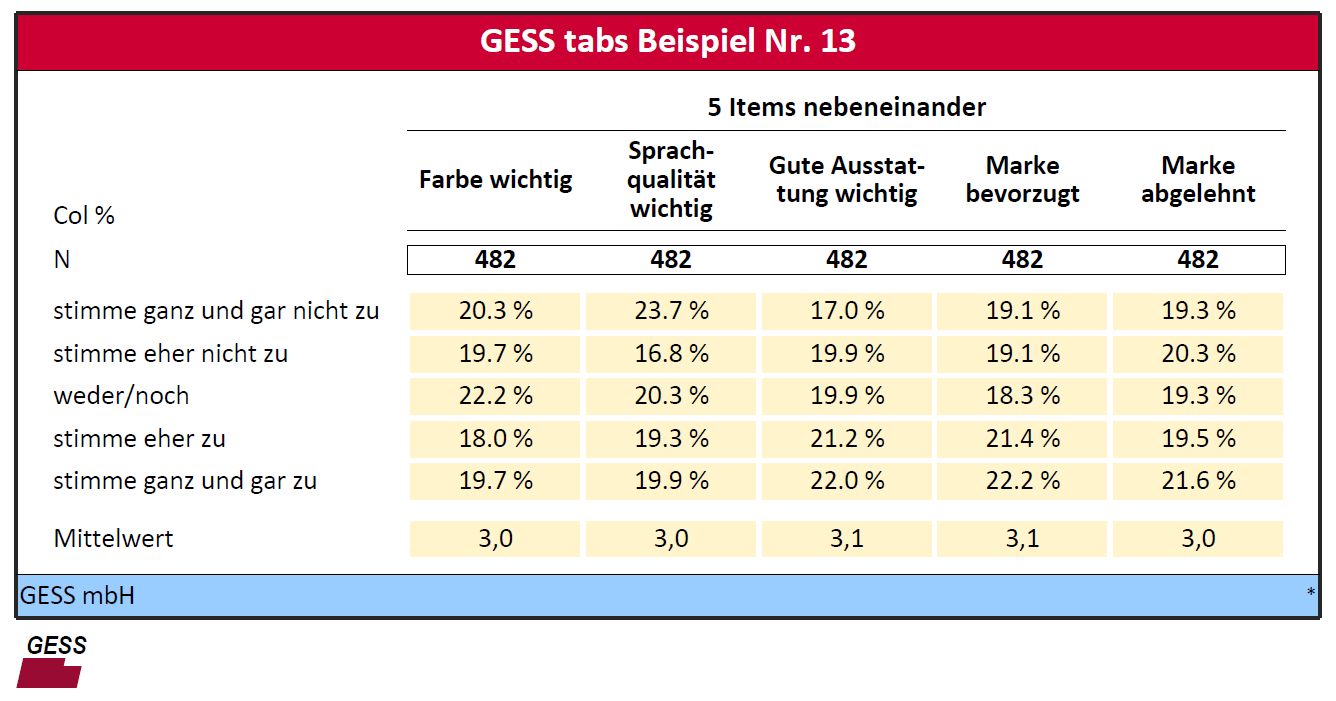
Man kann hier nun die Frage stellen, ob denn die Unterschiede im Mittelwert der Items signifikant sind, d.h. ob sie sich mehr unterscheiden, als man das aufgrund des Stichprobenfehlers erwarten würde. Dafür müssen wir das einfache CELLELEMENT MEAN durch das kombinierte CELLELEMENT MEANTEST, was einem Signifikanztest der Mittelwerte entspricht, ersetzen. Außerdem schalten wir zusätzlich das TABLEFORMAT AUTOSIGNCHAR ein. Dadurch werden in die Labelkästchen im Kopf Buchstaben gedruckt, die zum Querverweis dienen, im Vergleich zu welchen anderen Spalten ein Mittelwert signifikant unterschiedlich ist. Außerdem fordern wir einen Test auf niedrigem Level an: Als SIGNIFLEVEL soll LOWSIGNIFICANCE gelten. Und mit einem kleinen Trick erreichen wir, dass das Testniveau dokumentiert wird: wir bauen in die Tabelle einen leeren Bottomtext ein. Wenn eine Tabelle nämlich einen Bottomtext hat, wird der Beschreibungstext für das gewählte Signifikanzniveau dort angehängt. Diesen Bottomtext müssen wir vor die TABLE ADD-Statements schreiben, damit er der gedruckten Tabelle zugeordnet wird; die weiteren TABLE ADD-Statements bilden ja nur sogenannte "Zählschatten".
TABLEFORMAT = +AUTOSIGNCHAR;
SIGNIFLEVEL = LOWSIGNIFICANCE;
table = #k3 by item_1 meantest : description "Mittelwert" ( item_1 );
bottomtext = "";
table add = 2 by item_2 meantest : description "Mittelwert" ( item_2 );
table add = 3 by item_3 meantest : description "Mittelwert" ( item_3 );
table add = 4 by item_4 meantest : description "Mittelwert" ( item_4 );
table add = 5 by item_5 meantest : description "Mittelwert" ( item_5 );
Und das kommt dabei heraus: Solange wir mit einer relativ hohen Irrtumswahrscheinlichkeit von 10% leben können, darf der Unterschied zwischen Item_2 und Item_3 als signifikant gelten.

Signifikanz und Spaltenverweise
Wie man hier sieht, wird im Standardfall bei MEANTEST der Signifikanzhinweis für den Unterschied zwischen der Spalte B und der Spalte C zweimal ausgegeben: In der Spalte B steht ein kleines C und umgekehrt. Mit dem SHOWSIGNIF-Statement kann man das modifizieren. Mit SHOWSIGNIF MEAN = GREATER; wird nur bei dem größeren Mittelwert ein Spaltenverweis gedruckt:

Festlegen der Spaltenverweise
Ein Verbesserungsvorschlag: Es könnte doch ganz übersichtlich sein, wenn die Software die Stellen, an denen signifikante Mittelwertsunterschiede gefunden wurden, farblich kennzeichnen könnte. Es gibt generell die Möglichkeit, beliebigen Wertebereichen von CELLELEMENTS eigene Farben zuzuordnen. Die signifikanzbezogenen CELLELEMENTS liefern einen synthetischen Zahlenwert von 99999 zurück, wenn ein Test zum Ausdruck eines Signifikanzhinweises führt. Diesen Wert kann man nutzen, um eine Einfärbung der signifikant abweichenden Zellen zu erreichen. Die Klausel lautet:
RGB = YES;
COLOR FOREGROUND =
| MEANTEST RANGE 99998.9 99999.1 : 1 0 0
// rot!
;
Man kann mit dem COLOR-Statement wahlweise den Vordergrund oder den Hintergrund einfärben. Hier wird die Schrift selber, also der FOREGROUND, in knallrot geändert. Und im Ergebnis sieht das so aus:

Wertebereiche einfärben
Man kann nicht nur die Mittelwerte der Skalen gegeneinander testen, sondern auch die Spaltenprozente in den einzelnen Zeilen der Matrix können auf Signifikanz des Unterschieds getestet werden. Dazu muss man nur das entsprechende CELLELEMENT hinzufügen:
CELLELEMENTS = COLUMNPERCENT COLCHIQU;
Und da wir auch an dieser Stelle gern unseren farblichen Hinweis hätten, müssen wir auch das COLOR FOREGROUND-Statement erweitern:
RGB = YES;
COLOR FOREGROUND =
| MEANTEST RANGE 99998.9 99999.1 : 1 0 0
| COLCHIQU RANGE 99998.9 99999.1 : 1 0 0
;
Die erweiterte Tabelle sieht dann so aus:

Signifikanzen einfärben
Wenn nun gewünscht ist, die fünf Items nebeneinander für Männer und Frauen getrennt darzustellen, müssen wir im Grund dieselben Inhalte zweimal darstellen, jeweils nach dem Geschlecht gefiltert. Am einfachsten kann man die Fälle, die in eine Tabelle eingehen sollen, über TABSELECT oder TABLEFILTER steuern. Dies betrifft aber immer die gesamte Tabelle. Darüber hinaus gibt es aber auch die Möglichkeit, über eine Filterklausel Filterungen innerhalb des TABLE-Statements nur für einzelne Tabellenbestandteile anzufordern.
Im Anschluss an jedes angeforderte Tabellenelement kann man durch FILTER <Bedingung> | eine interne Selektion anfordern.
Es ist also als Beispiel eine Tabelle wie eben gefordert, aber sie soll zwei Teile enthalten, einen für die Männer und einen für die Frauen. Als erstes benötigen wir für den Kopf ein #EXPAND, das zwei Dummyvariablen enthält, für die Titel "Männer" und "Frauen". Diesen Dummyvariablen geben wir gleich passende Filter:
compute dummy5_2 dummy5_3 = 1;
copylabels
dummy5_2 dummy5_3 = dummy5;
filter dummy5_2 = geschl eq 1;
vartitle dummy5_2 = ’Männer’;
filter dummy5_3 = geschl eq 2;
vartitle dummy5_3 = ’Frauen’;
#expand #k4 dummy5_2 dummy5_3
Eine Alternative zur Erzeugung der gewünschten Tabelle wäre jetzt, für Item_2 bis Item_5 ähnliche Dummyvariablen zu bauen. Einfacher ist es allerdings, von der oben beschriebenen Möglichkeit Gebrauch zu machen, die Tabellenbestandteile direkt im TABLE-Statement zu filtern. Die Anweisungsfolge sieht dann insgesamt so aus:
CELLELEMENTS = COLUMNPERCENT COLCHIQU;
TABLE= #k4 BY item_1 MEANTEST
: DESCRIPTION "Mittelwert" ( item_1 );
bottomtext = "";
TABLE ADD = 2 FILTER geschl EQ 1 | 2 FILTER geschl EQ 2 | BY item_2 MEANTEST
: DESCRIPTION "Mittelwert" ( item_2 );
TABLE ADD = 3 FILTER geschl EQ 1 | 3 FILTER geschl EQ 2 | BY item_3 MEANTEST
: DESCRIPTION "Mittelwert" ( item_3 );
TABLE ADD = 4 FILTER geschl EQ 1 | 4 FILTER geschl EQ 2 | BY item_4 MEANTEST
: DESCRIPTION "Mittelwert" ( item_4 );
TABLE ADD = 5 FILTER geschl EQ 1 | 5 FILTER geschl EQ 2 | BY item_5 MEANTEST
: DESCRIPTION "Mittelwert" ( item_5 );
Es entsteht die gewünschte Tabelle:

Bestandteile einer Tabelle können durch Filter bestimmt werden
Nun kann man natürlich auch den Wunsch haben, die Männer und die Frauen nicht nebeneinander darzustellen, sondern übereinander. Ein Weg dahin ist, für die fünf Items jeweils nach dem Geschlecht gefilterte Variablen zu erstellen. Dies passiert mit den folgenden Makros:
#macro #m( &1 )
COMPUTE m_item_&1 = item_&1;
FILTER m_item_&1 = geschl eq 1;
COPYLABELS m_item_&1 = item_&1;
VARTITLE m_item_&1 = ’Männer’;
#endmacro
#macro #f( &1 )
COMPUTE f_item_&1 = item_&1;
FILTER f_item_&1 = geschl eq 2;
COPYLABELS f_item_&1 = item_&1;
VARTITLE f_item_&1 = ’Frauen’;
#endmacro
Neben dem "normalen" Aufruf von Macros gibt es zusätzlich die #DOMACRO-Anweisung. Damit können wir die benötigten zehn Variablen am ökonomischsten erstellen:
#domacro ( m 1:5 )
#domacro ( f 1:5 )
Nach dem Aufruf der Makros gibt es zusätzlich zehn Variablen: m_item_1 bis m_item_5 für die Männer und entsprechend fünf Variablen für die Frauen. Um nicht immer wieder die :DESCRIPTION-Klausel schreiben zu müssen, wird das TABLEFORMAT MEANDESCRIPTION eingeschaltet und dem MEANTEST der Beschreibungstext "Mittelwert" zugeordnet.
Damit die Filterung über die gefilterten Variablen greift, wird in einer USECASES-Klausel vereinbart, dass nur die Fälle eingehen sollen, die in der Y-Richtung tabellierten Variablen gültig (= nicht gefiltert) sind. Das TABLEFORMAT -NOVARTITLEBOX sorgt dafür, dass links oberhalb der Labels die Vartitle für die Männer und Frauen stehen. Die Tabellenanweisung sieht dann folgendermaßen aus:
FRAMEELEMENTS =;
USECASES = YVALID;
TABLEFORMAT = +MEANDESCRIPTION -NOVARTITLEBOX;
DESCRIPTION MEANTEST = Mittelwert;
CELLELEMENTS = COLUMNPERCENT COLCHIQU;
TABLE = #k3 BY m_item_1 MEANTEST ( m_item_1 ) f_item_1 MEANTEST ( f_item_1 );
BOTTOMTEXT = "";
TABLE ADD = 2 BY m_item_2 MEANTEST ( m_item_2 ) f_item_2 MEANTEST ( f_item_2 );
TABLE ADD = 3 BY m_item_3 MEANTEST ( m_item_3 ) f_item_3 MEANTEST ( f_item_3 );
TABLE ADD = 4 BY m_item_4 MEANTEST ( m_item_4 ) f_item_4 MEANTEST ( f_item_4 );
TABLE ADD = 5 BY m_item_5 MEANTEST ( m_item_5 ) f_item_5 MEANTEST ( f_item_5 );

Weitergehende Filter
Das Variablengerüst zu dem Beispielen:
variable geschl = * 1 labels
1 "Männlich"
2 "Weiblich";
title="Geschlecht";
text="Geschlecht des Befragten";
helptext="nicht fragen: Interviewereinschätzung";
nomissing=yes;
variable alter = * 1 labels
1 "18-29 Jahre"
2 "30-49 Jahre"
3 "50-64 Jahre";
title="Alter";
text="Alter des Befragten";
nomissing=yes;
familyvar bekannt = * 9 1 labels
1 "iPhone"
2 "LG"
3 "Samsung"
4 "Huawei"
5 "Asus"
6 "Xiaomi "
7 "Sony"
8 "Nokia"
9 "keine davon" bottom single always;
title="Bekannte Marken von Mobiltelefonen";
text="Welche dieser Mobiltelefone kennen Sie?";
nomissing=yes;
FAMILYVAR gekauft = * 9 1 LABELS copy bekannt;
title="Gekaufte Marken von Mobiltelefonen";
text="Welche dieser Mobiltelefone haben Sie sich schon einmal gekauft?";
nomissing=yes;
variable item_1 = * 1 labels
1 "stimme ganz und gar nicht zu"
2 "stimme eher nicht zu"
3 "weder/noch"
4 "stimme eher zu"
5 "stimme ganz und gar zu";
title="Die Farbe ist mir wichtig";
text="Bitte stufen Sie dieses Item ein:
Die Farbe ist mir wichtig";
variable item_2 = * 1 labels
1 "stimme ganz und gar nicht zu"
2 "stimme eher nicht zu"
3 "weder/noch"
4 "stimme eher zu"
5 "stimme ganz und gar zu";
title="Eine gute Sprachqualität ist mir wichtig";
text="Bitte stufen Sie dieses Item ein:Eine gute Sprachqualität ist mir wichtig";
variable item_3 = * 1 labels
1 "stimme ganz und gar nicht zu"
2 "stimme eher nicht zu"
3 "weder/noch"
4 "stimme eher zu"
5 "stimme ganz und gar zu";
title="Eine gute Ausstattung ist mir wichtig";
text="Bitte stufen Sie dieses Item ein: Eine gute Ausstattung ist mir wichtig";
variable item_4 = * 1 labels
1 "stimme ganz und gar nicht zu"
2 "stimme eher nicht zu"
3 "weder/noch"
4 "stimme eher zu"
5 "stimme ganz und gar zu";
title="Ich bevorzuge generell eine bestimmte Marke";
text="Bitte stufen Sie dieses Item ein: Ich bevorzuge generell eine bestimmte Marke";
variable item_5 = * 1 labels
1 "stimme ganz und gar nicht zu"
2 "stimme eher nicht zu"
3 "weder/noch"
4 "stimme eher zu"
5 "stimme ganz und gar zu";
title="Ich lehne eine bestimmte Marke generell ab";
text="Bitte stufen Sie dieses Item ein: Ich lehne eine bestimmte Marke generell ab";
random = item_1 item_2 m_3 item_4 item_5;